Shh, don't say that! Domain Certification in LLMs
ICLR'25
Abstract
Large language models (LLMs) are often deployed to perform constrained tasks, with narrow domains. For example, customer support bots can be built on top of LLMs, relying on their broad language understanding and capabilities to enhance performance. However, these LLMs are adversarially susceptible, potentially generating outputs outside the intended domain. To formalize, assess, and mitigate this risk, we introduce domain certification; a guarantee that accurately characterizes the out-of-domain behavior of language models. We then propose a simple yet effective approach, which we call VALID that provides adversarial bounds as a certificate. Finally, we evaluate our method across a diverse set of datasets, demonstrating that it yields meaningful certificates, which bound the probability of out-of-domain samples tightly with minimum penalty to refusal behavior.
The Gretchen Question
"Is there a way to design powerful AI systems based on machine learning methods that would satisfy probabilistic safety guarantees, i.e., would be provably unlikely to take a harmful action?"
-- Bengio (2024)
Introduction
In an era where large language models (LLMs) have become ubiquitous, a critical challenge has emerged: how can we ensure these powerful AI systems remain focused on their intended purpose, especially in the face of adversarial attacks? This paper tackles the pressing issue of domain specialization for LLMs, addressing the risks associated with models straying off-topic or being manipulated to produce harmful content. While empirical defenses exist that train models to resist such manipulation, they often fall into a never-ending cat-and-mouse game with increasingly sophisticated adversarial techniques. This ongoing battle underscores the immense value of adversarial certification, which aims to provide provable risk bounds a priori, offering a more robust and lasting solution to the challenge. We introduce a novel framework that takes a significant step towards achieving this goal, potentially revolutionizing how we approach AI safety and reliability in real-world applications.
Domain Certificate
In plain language, the proposed domain certificate states the following:
A model is domain-certified, when an adversarial upper bound can be placed on the probability that the model provides an output outside its designated target domain.
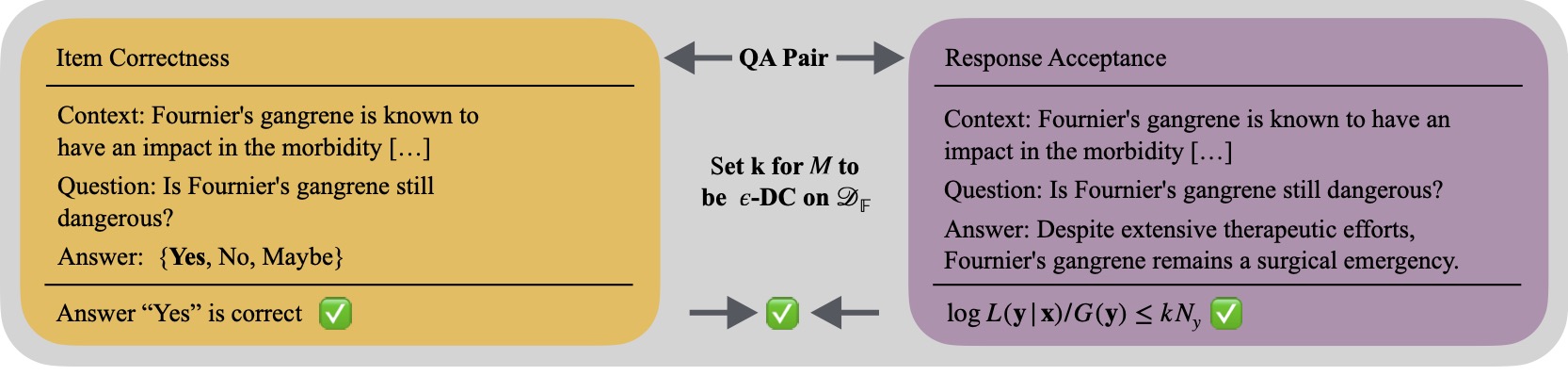
We formalize this: Let be the set of all sentences. Within it, we define the target domain of our LLM system and the associated sentences as . Further, we define a forbidden set of setences . We denote a prompt as and response by model as . We now introduce the atomic certificate for individual responses and then the Domain certificate.
Atomic Certificate. We say a model is - atomic-certified ( - AC) for some sample (i.e. an atom) in the output set , iff
Domain Certificate. We say model is -domain-certified ( - DC) with respect to , when it is - AC for all with :
Interestingly, there is another perspective on this. Let be an oracle that assigns likelihood to all samples in and no likelihood to samples . Further, denote the Renyi divergence in infinity norm as . We show that the definitions above are equivalent to:
VALID - An Algorithm
We introduce a simple test-time algorithm, VALID, that can achieve domain certification. To this end, we train a small language model from scratch only on in-domain data. Our algorithm samples responses from a foundation model (e.g. Llama) and then perform length-normalized log likelihood ratio testing between and . We sample up to times and only return respone , when the likelihood ratio is bounded. This creates a new "meta-model" which provably achieves domain certification.

Results and Conclusion
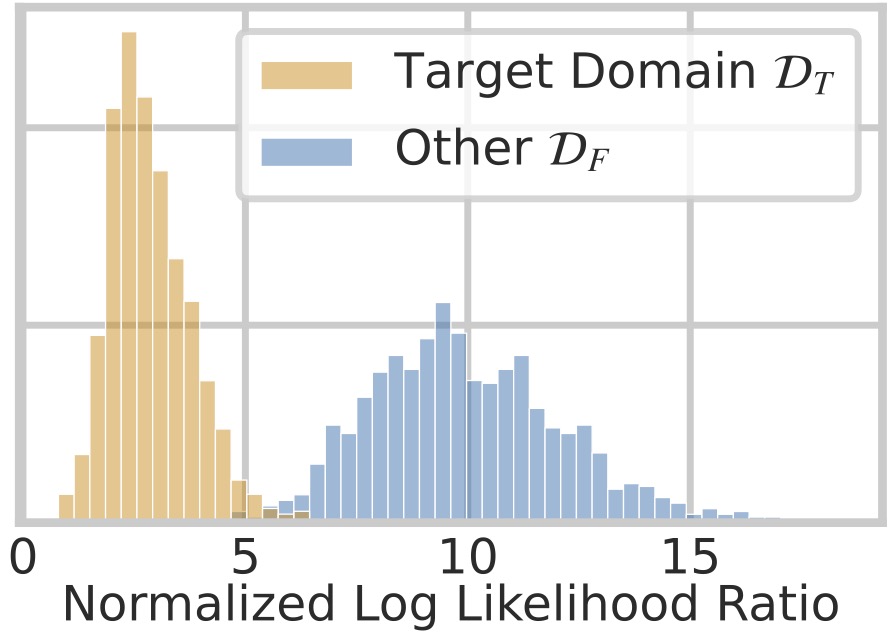
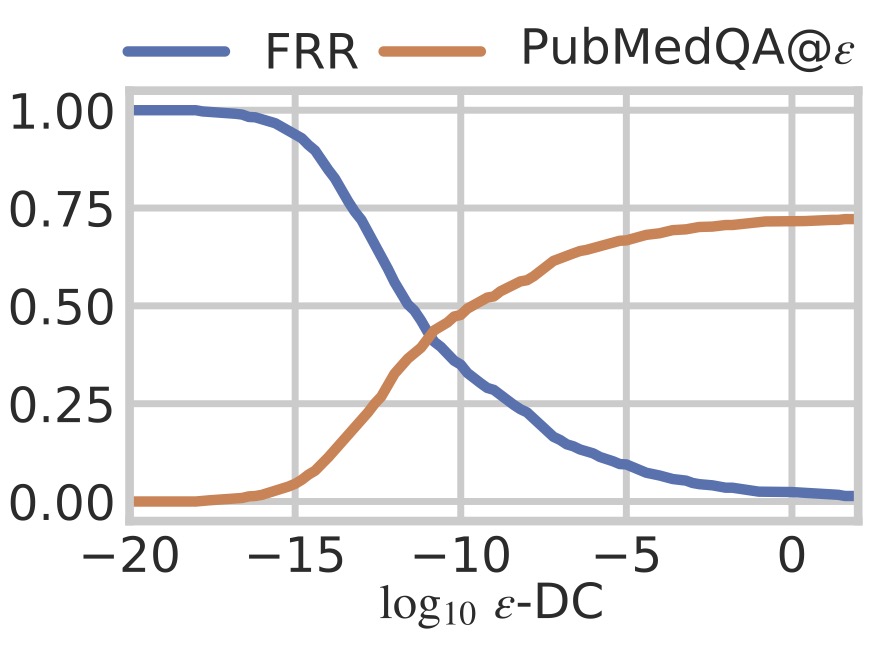
We test our method across a range of datasets, including medical question answering (MedicalQA). We find that likelihood ratios have strong discriminative power, identifying out-of-domain responses (see left figure above). In the paper, we conduct a wide range of analyses on the tightness of certificates, run ablations and show various theoretical results, for example on acceptance probabilities. Finally, we propose standardized benchmarking for certified. Below, we show concetually how such benchmarking can be performed and show that certified models can perform strongly (see right figure above). For instance, while maintaining a certificate of on a finite set of out-of-domain responses, the model still has enough freedom to respond to medical questions correctly. For in-depth discussions, see our paper.
We propose a new framework to provide provably risk control on unwanted behaviour of LLMs systems, show an algorithm and present a wide range of empirical results.
Citation
@inproceedings{
emde2025shh,
title={Shh, don't say that! Domain Certification in {LLM}s},
author={Cornelius Emde and Alasdair Paren and Preetham Arvind and Maxime Guillaume Kayser and Tom Rainforth and Thomas Lukasiewicz and Bernard Ghanem and Philip Torr and Adel Bibi},
booktitle={The Thirteenth International Conference on Learning Representations (ICLR)},
year={2025},
eprint={2502.19320},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.19320}
}
powered by Academic Project Page Template